





 Research Assistant at The Research Foundation SUNY
April 2024 ‑ Present
Research Assistant at The Research Foundation SUNY
April 2024 ‑ Present
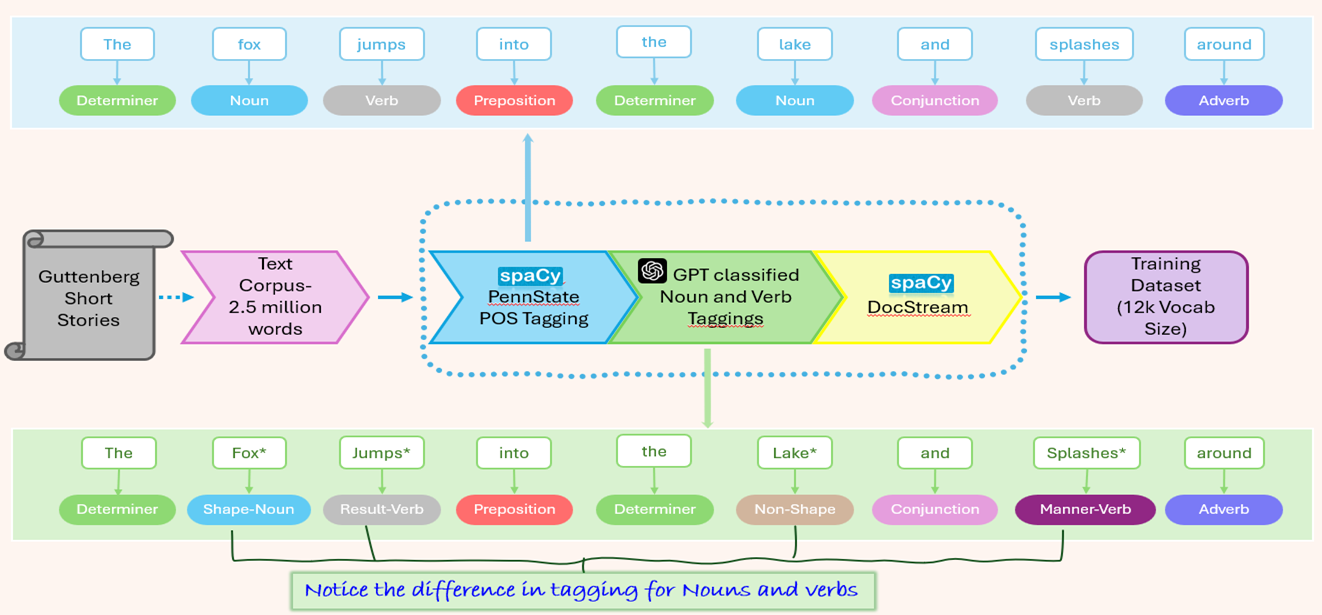
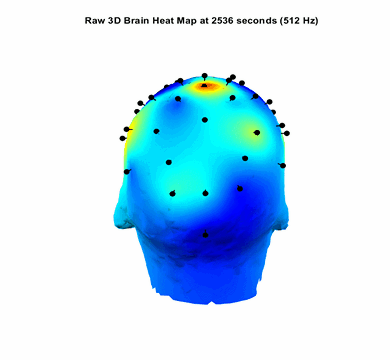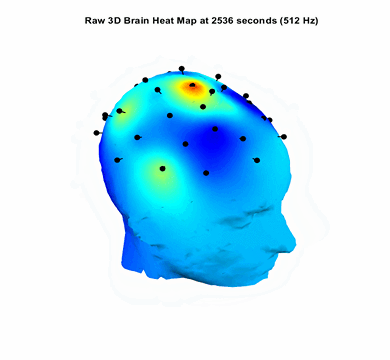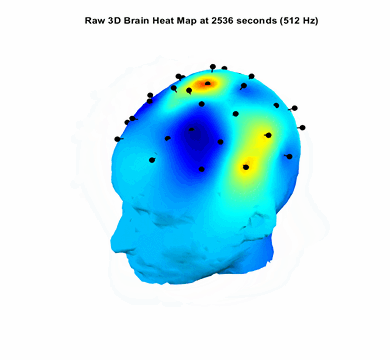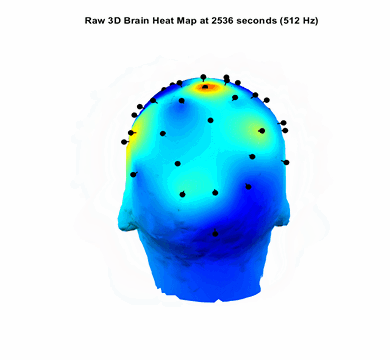
Modelled and trained a 25M parameterActive Speaker Detection model on Oxford Voxceleb, and Google AVA, AVSpeech dataset consisting of 2 Million videos to generate Lip Sync Scores. The model performs with a 0.89 F1 score. Major improvement is this is the first near Realtime Active Speaker Localization model that works on live camera feed with a latency of 1.2 seconds. All other pipelines works only on offline videos.
 Data Science Lead Assistant Manager at EXL Analytics
Data Science Lead Assistant Manager at EXL Analytics
 Analytics Deputy Manager at Suzuki Motors India Limited
Analytics Deputy Manager at Suzuki Motors India Limited
 Software Verification & Validation Intern at Alstom Transport
Software Verification & Validation Intern at Alstom Transport
